Introduction
Artificial intelligence (AI) algorithms have become ubiquitous in our lives, and the field of assisted reproductive technology (ART) is no exception. In recent years, increasingly many publications in scientific journals and conferences have highlighted the various applications of AI in reproductive medicine [1,2]. These applications span a wide range of areas within the field of reproductive medicine [3-5]. As embryologists, as well as physicians, we have the duty to keep abreast of the existing technologies, and above all, their function and results, before accepting the incorporation of any new tool in clinical practice. The present work aims to provide key concepts to be taken into consideration when considering integrating AI systems into reproductive medicine practices.
Artificial intelligence in assisted reproductive technology
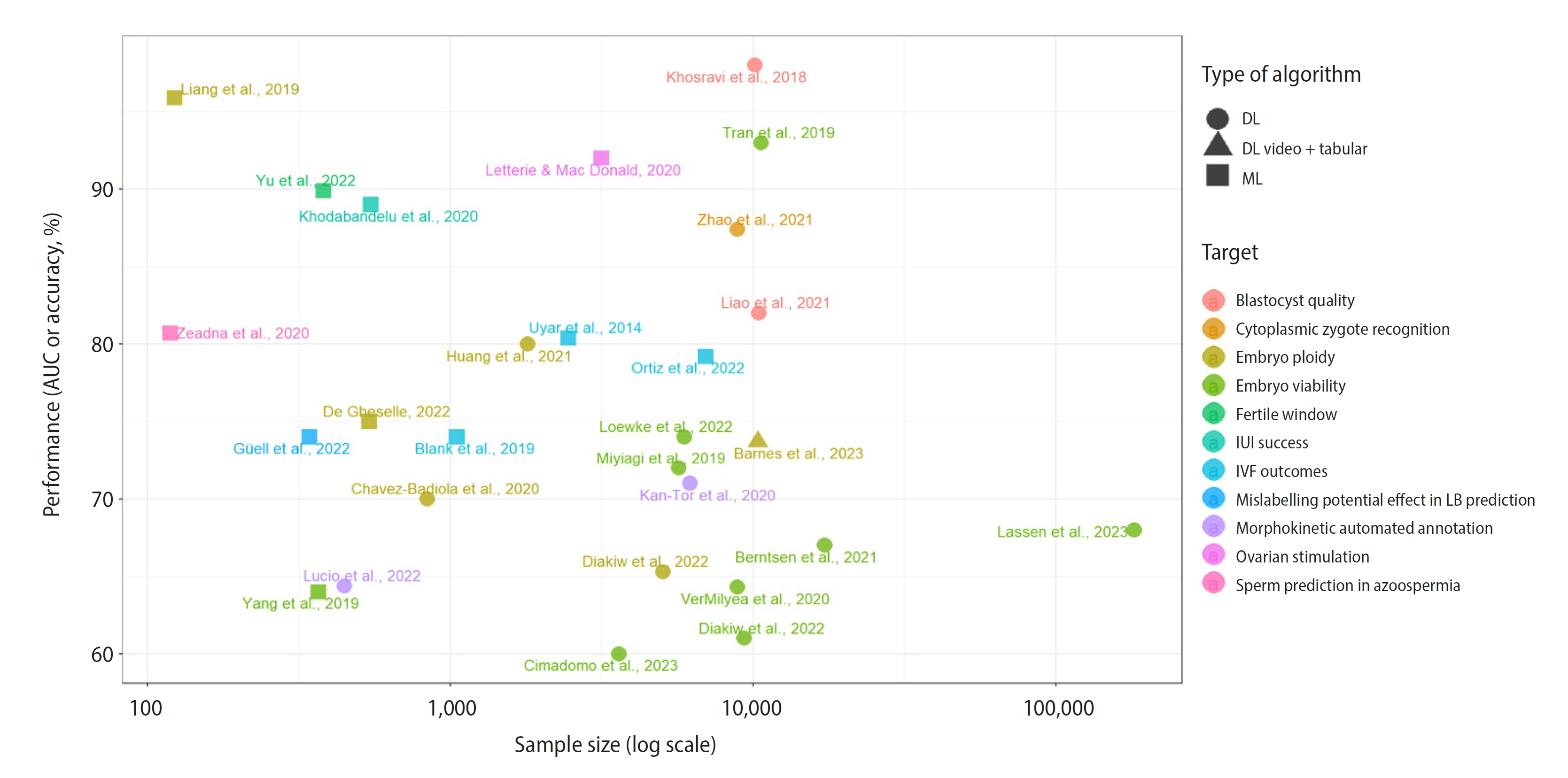
Among the numerous published algorithms, we can find predictive models for embryo transfer outcomes on day 2/3 [6] and blastocyst stage [7,8], sperm selection by image recognition correlated with fertilization and blastocyst formation [9], prediction of obtaining spermatozoa from testicular biopsies [10], non-invasive oocyte scoring on two-dimensional images [11], cytoplasmic recognition of the zygote [12], morphokinetic automated annotation of the embryo [13-15], automated blastocyst quality assessment [16], embryo implantation potential via morphokinetic biomarkers [17], euploidy prediction using metabolic footprint analysis [18], ranking for embryo selection [19-25], blastocoel collapse and its relationship with degeneration and aneuploidy [26], morphokinetics and clinical features for the prediction of euploidy [27], prediction of aneuploidy or mosaicism using only patients’ clinical characteristics [28], tracking of menstrual cycles and prediction of the fertile window [29], control of culture conditions and quality control of embryologist performance [25,30], intrauterine insemination success [31], computer decision support for ovarian stimulation [32], prediction for the day of triggering [33,34], and follicle-stimulating hormone dosage prediction for ovarian stimulation [35]. All the mentioned references are depicted in Figure 1. Machine learning models are listed in Table 1 [6,7,10,17,18,27-29,31-37], while those corresponding to the deep learning subset can be found in Table 2 [8,9,11-16,19-24,26,38-43]. In these tables, the AI models are described with their sample size, results and limitations. The main limitation of all studies was their retrospective nature. A limited sample size, imbalanced dataset, and lack of multi-center evaluation were also common limitations found in the literature review.
Commercial platforms or in-house algorithms
The AI systems used in in vitro fertilization (IVF) clinics can be categorised into two types: commercial products and self-developed in-house solutions. While cloud-based systems can offer advantages for IVF clinics with lower workloads, such as leveraging data from other clinics, they may face challenges in maintaining predictive accuracy due to interference from individual clinic protocols or conditions. Notable examples of cloud-based products include Embryo Ranking Intelligent Classification Algorithm (ERICA) [19], intelligent Data Analysis Score (iDAScore) [23], and Life Whisperer [20].
In contrast, adopting an in-house approach could offer certain advantages, such as greater control and customisation over the AI system and its workflow as well as the possibility to test own ideas without having to wait for commercial releases. Single-center studies such as Zeadna et al. [10] or De Gheselle et al. [27] represent this approach to AI in IVF.
Requirements for implementing new AI systems in the laboratory
Prior to introducing a new AI system—or any other technique—it is essential to ensure that it satisfies certain criteria in a laboratory setting. At least one of the following criteria should be met for the new technique to be considered suitable: the candidate AI system should have the ability to improve results, such as the live birth (LB) rate, time to pregnancy, or any other key performance indicator. If the results are not worsened, other criteria to be met could include making work easier and more efficient, saving time and resources, offering greater safety through an improved error detection, or providing better explainability.
Factors to consider when introducing AI in the laboratory
There are several factors that cannot be overlooked when considering the integration of a new system into the laboratory. These factors must be carefully evaluated before making a decision. When introducing an AI system, the following factors must be taken into account:
1. User interface
The user interface (the visual display on the screen) should be easy to understand and navigate.
2. Scalability
The system should be capable of adapting to the laboratory's needs, including the volume of data and users, as well as being integrated into the laboratory's workflow and protocols. If the AI platform cannot be adapted to the laboratory’s existing workflow, it is necessary to evaluate the impact of adapting the lab workflow and the potential benefit of using that AI platform.
3. Training
The manufacturer should offer information regarding the required training for users and how it will be delivered.
4. Support
The manufacturer should specify the type of technical support offered, who will be responsible in case of failure, and what the response time will be.
5. Follow-up
As AI systems continuously learn, it is crucial to ensure that the algorithms are updated to accommodate new data. The manufacturer should provide information about the maintenance and monitoring plan to ensure that the system continues to provide accurate and unbiased results.
6. Cost
The cost of a system should be considered in relation to the center’s budget and investment capacity.
7. Ethics
To ensure that an AI system is ethically sound, it is important to evaluate its impact on patient care and outcomes. The system should not only improve patient outcomes but also avoid any harm or negative impact on the patient. Moreover, the manufacturer should have measures in place to ensure the confidentiality and security of patient data, such as the ISO 27002-2021 and IEC 62304 standards. The most important ethical issue is the lack of randomised controlled trials. It is premature to implement a technology in the clinical setting before the trial results are made available [44]. The nature of the mathematical algorithms performed during the AI process leads to a spectrum of transparency, ranging from the most interpretable models, such as linear regression-based algorithms, to the most cryptic models, also called black-box, such as neural networks. It is important to know the risks, side effects, benefits and the confidence of each clinical decision before delegating the decision-making process to machines. While transparent models enhance clinical decision-making, black-box systems replace human decisions, leading to uncertainty about the responsibility for treatment success. Black-box algorithms could build predictive models biased by cofounders, and the error-checking processes of each prediction could go unnoticed by human operators [44]. Moreover, opaque models could increase the risk of imbalanced outcomes. For instance, if there exists a correlation between embryo quality assessed by AI and gender, there could be an intrinsic imbalance that could take more time to detect than in interpretable models.
8. Data quality
The quality of data refers to the data’s accuracy, completeness, timeliness, relevance, consistency, and reliability. It is crucial for an AI system to have access to high-quality data to provide accurate and reliable results. If the data used for building the model are not reliable and generalisable, then the AI model will fail when applied to new data in the near future. Some models are based on a concrete and certain population, and if data across populations are not as homogeneous, then the model will not be accurate enough. Furthermore, in embryology, confounding factors such as age should not be used as predictors in embryo quality models if it is desired to develop an embryo quality model instead of an age-based predictive model [44], as the AI algorithm could base its prediction mostly on data included in the age variable with no importance for embryonic features.
Data annotation
The source of data is crucial in data annotation. The origin of data can vary (tabular, images, videos, audio, the outcome of a previous AI algorithm, etc.), and the annotation of data is expected to be more effective when automated, since automation removes the subjectivity of human-annotated parameters. However, the effectiveness of automated versus manual annotation depends on the degree of intra-individual and inter-individual variability for the target variable when annotated by humans and the reliability of the automatic annotation methods [45,46]. Features with higher variability or lower reliability can lead to lower performance of predictive models, since AI may use different values for data that are actually equivalent. Including such features in the models can introduce noise or inconsistencies, affecting the accuracy of predictions and the model’s overall performance. Determining whether manual or automated annotation is more suitable depends on each specific case. Factors such as data complexity, available resources, and the desired level of accuracy need to be considered. Manual annotation can provide more accurate and reliable results, but can be time-consuming and introduce human biases. Automated annotation methods can be more efficient and scalable, but may be less accurate or reliable, especially in cases with noisy data or lack of proper validation.
It is not always possible for all values in a database to be filled. Not available (NA) values represent a problem when building AI algorithms and require proper handling. Several options exist for managing missing values. Some common approaches include discarding observations with NA values, imputing missing values using methods such as mean or median imputation, or utilising other AI algorithms such as k-nearest neighbour for imputation, as well as directly excluding the feature with NA values.
Machine learning techniques are also sensitive to data points that deviate significantly from the majority of the data (outliers). Managing outliers involves deciding whether to integrate them into the analysis or discard them.
Therefore, careful consideration is required when dealing with NA values and outliers. The choice of appropriate strategies for managing them depends on the specific context, the nature of the data, and the objectives of the analysis.
Risk factors affecting data quality in model design
Each predictive model has its unique characteristics and objectives, and is based on a specific experimental design that includes certain factors as inclusion and exclusion criteria. It is crucial to carefully review the experimental design, as there could be potential risks that may affect the quality of data used in the model. One such risk would be the possibility of data bias due to the inclusion criteria, which could compromise the generalisability of the results, particularly if there were confounding factors affecting predictive variables [47,48]. Three additional pitfalls to consider, as described by Curchoe et al. [49], are small sample sizes, imbalanced datasets, and limited performance metrics.
Furthermore, in classification cases, there could exist a risk of mislabelling in the output variable. Mislabelling occurs when the categorical variable has incorrect labels for some of the data points. It is important to be aware of this risk, as the inclusion of mislabelled data decreases accuracy [50,51]. A potential example of mislabelling in embryology is evident in two embryo selection models with different labels for classification. One model compares implanted or LB embryos versus non-implanted or non-live birth (NLB) embryos [38], while the other compares euploid versus aneuploid embryos [39]. In the LB versus NLB comparison, it is important to carefully consider the potential for mislabelling, as high-potential embryos with a negative outcome due to reasons unrelated to the embryo could be incorrectly labelled as NLB, which may negatively impact the performance of machine learning and deep learning algorithms [36,40,52]. Additionally, in ploidy models, undetected mosaicism [53] can also lead to mislabelling. Moreover, the "Schrödinger embryo" paradox makes it impossible to assess the genetic status of the inner cell mass and trophectoderm until the whole embryo has been donated for research. Once an embryo has been donated, it becomes impossible for it to achieve LB, and its real potential for viability will remain unrealised. Besides, the algorithms’ performance may be distorted depending on the inclusion criteria in each experimental design. There is a risk of including embryos with low viability potential, those that have not yet been transferred, or even euploid embryos that were not cryopreserved due to low quality [54]. Specifically, Tran et al. [41] reported that the area under the curve (AUC) could be inflated by including many arrested embryos in the sample used to compute it. That predictive model could be considered proper for justifying automation for the quality assessment of arrested embryos, although random choice was supposed to be used for non-arrested embryos [55].
Machine and deep learning modelling
Machine and deep learning modelling refer to the process of creating and training mathematical models that can automatically identify patterns and make predictions or decisions based on data. Deep learning is included in the broader category of machine learning category. These models are built using algorithms and statistical techniques that allow computers to learn from large datasets and improve their performance over time [56]. To emphasise the main differences, it is worth noting that machine learning typically requires fewer data points and provides greater interpretability than deep learning. As a rule of thumb, the sample size should be at least 10 times the number of parameters in an algorithm, and it is generally easier to determine this value for machine learning models than for deep learning models [17].
There are two primary types of machine learning algorithms: supervised and unsupervised. On the one hand, supervised learning is an approach in which a model is trained using labelled data. After introducing input features (independent variables) along with corresponding target labels (dependent variable), supervised learning tries to learn a function or a relationship between the input features and the target labels. Once trained, the model can make predictions or classify new instances based on the input features. Supervised learning is commonly used in prediction and classification problems, where the objective is to predict a specific outcome or category, although numerical values can also be predicted through regression models. Decision trees, scoring systems, generalised additive models, and case-based reasoning are among the primary techniques used in various supervised learning algorithms [57]. Each algorithm has its own specific characteristics and uses. Linear regression involves fitting a linear equation to the data, enabling the prediction of continuous target variables [35]. Logistic regression is mainly used for binary classification tasks, although it could also be useful for multi-class problems, by modelling the probability of an event occurring based on input features [31]. Recursive partitioning is a technique commonly used in decision trees, where the data are recursively split into subsets based on certain conditions of features [57]. Random forest is an ensemble learning method that combines multiple decision trees to improve prediction accuracy and reduce overfitting [17,31]. The k-nearest neighbour method classifies or predicts the value of a data point based on the values of its k-nearest neighbours in the feature space [34,57]. Gradient boosting is an ensemble technique that builds a strong predictive model by iteratively combining multiple weak models, often decision trees, to correct errors made by the previous models [31]. Support vector machines construct hyperplanes in a high-dimensional feature space to separate different classes or estimate continuous target variables [31,57]. Neural networks are complex and versatile machine learning algorithms capable of handling various tasks, including classification, regression and pattern recognition. They are inspired by the structure of the human brain. Image recognition models are based on this type of algorithms [13,16,19,20].
On the other hand, unsupervised learning is employed in situations where the training data lack pre-existing labels or outcomes. Its objective is to discover patterns or structures inherent in the data without explicit guidance and to uncover similar groups or clusters of data. This type of learning is useful for exploring and comprehending the underlying structure in data and identifying hidden patterns. Clustering algorithms and dimensionality reduction methods are widely used in the field of unsupervised learning. K-means is a popular clustering algorithm aiming to divide a dataset into distinct groups or clusters based on similarity. The algorithm iteratively assigns data points to the nearest cluster centroid and updates the centroids until convergence [17]. Principal component analysis (PCA) is a dimensionality reduction technique that transforms a high-dimensional dataset into a lower-dimensional space by identifying the principal components that capture the most significant variance in the data. These principal components are orthogonal and ordered in terms of their explanatory power. PCA is useful for simplifying complex datasets, visualising data in lower dimensions, and identifying the most important features driving variability in the data [56].
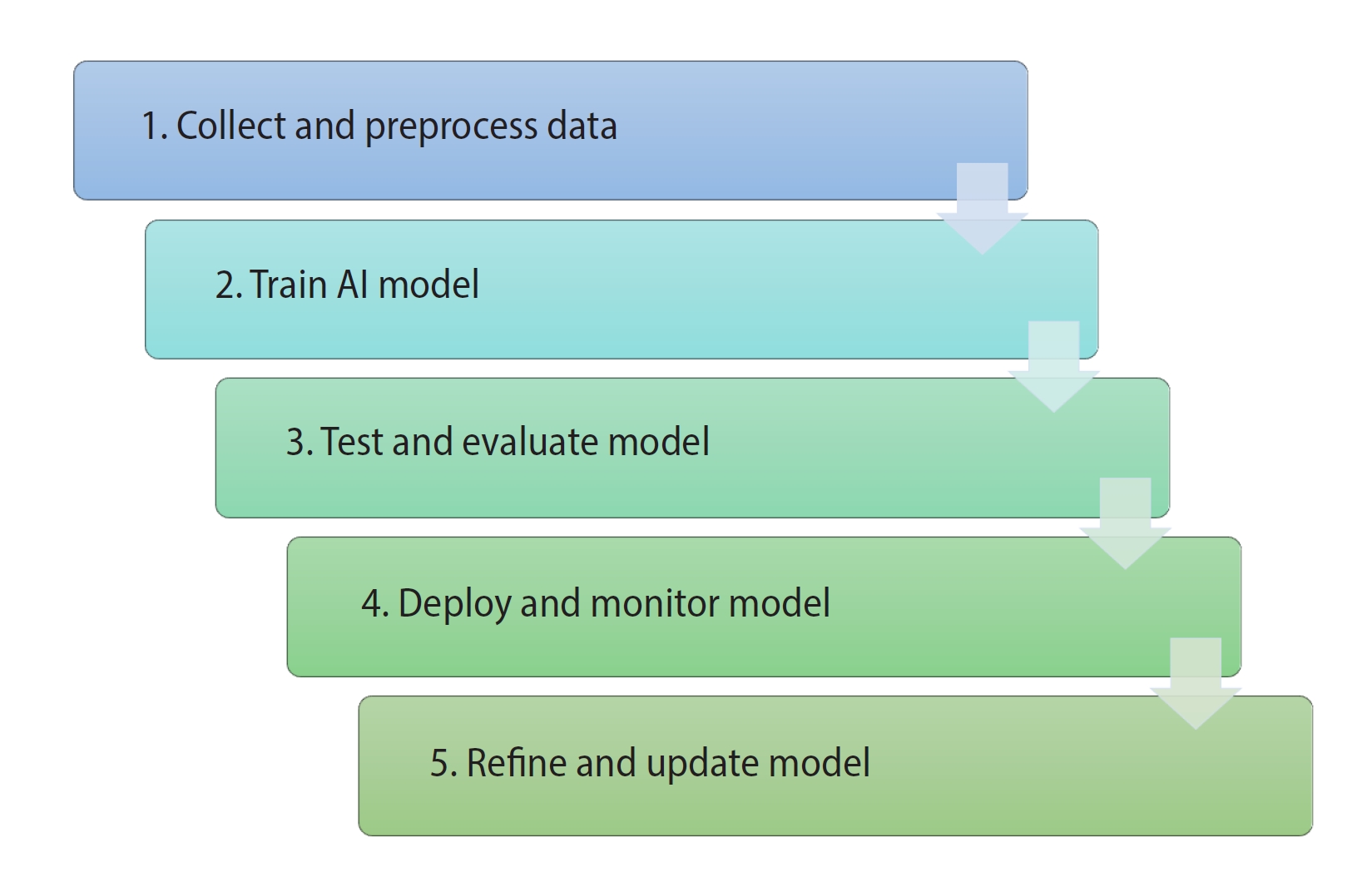
Thus, the algorithms used in assisted reproduction to predict categories using labelled data are of the supervised learning type. When encountering AI-based predictive models, clinicians and embryologists should be familiar with the machine learning lifecycle (Figure 2):
(1) Collect and pre-process data: Collect relevant data and carry out pre-processing (cleaning, normalising, transforming, etc.) to prepare the data for machine learning algorithms.
(2) Train a machine learning model: Train a machine learning model on the pre-processed data using a suitable algorithm and hyperparameters.
(3) Test and evaluate the model: Test the trained model on a separate test dataset and evaluate its performance using suitable evaluation metrics.
(4) Deploy the model: Deploy the trained model to a production environment, such as a web application or a mobile app.
(5) Monitor the model: Continuously monitor the performance of the deployed model and collect feedback from users.
(6) Refine and update the model: Refine and update the deployed model periodically using new data and feedback to improve its performance and adapt to changing requirements.
Performance evaluation and model validation
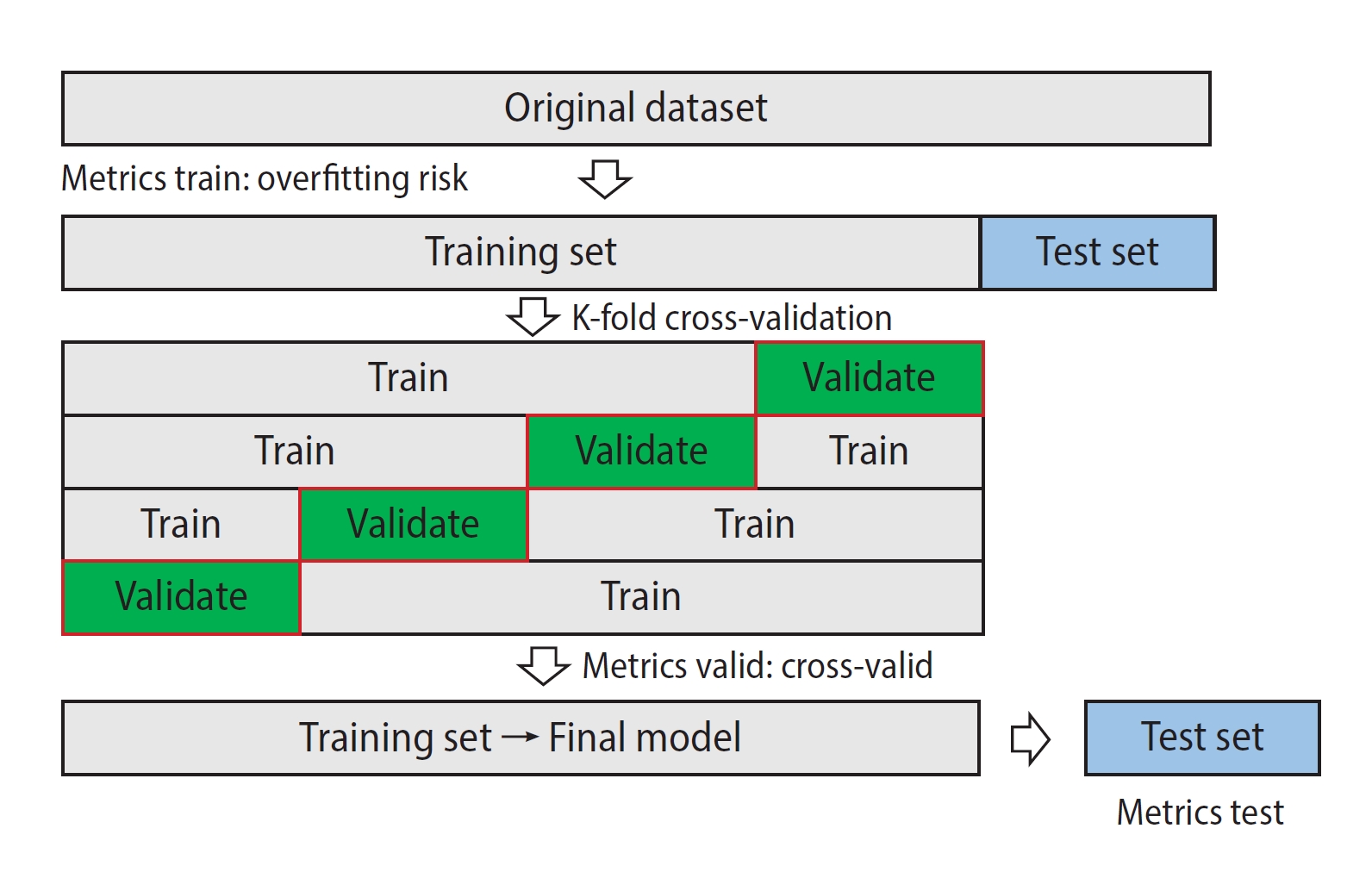
When discussing performance, the first step is to define what is being evaluated. If one encounters studies that claim remarkable results on the training dataset, it is advisable to exercise caution. Predicting data that are already in the system makes it easier for the computer to find a previous pattern in the known model, leading to the overfitting effect. It is entirely normal, and almost necessary, for the training set results to be particularly good, as they do not represent the actual predictive potential of the model.
As showed in Figure 3, the process of developing a predictive model involves an initial partition of the test set, which is kept separate from the algorithm's training. Cross-validation is performed on the training set by separating a certain percentage and creating the model with the training set, then predicting the validation set. This process can be repeated several times to obtain cross-validation metrics. This prediction can already be considered representative of the model's predictive potential. Cross-validation can be performed through k-fold cross-validation (e.g., 80% of the dataset for training and 20% for validation) [18,28]; as well as training the model with the full dataset except for one specimen, predicting it, and repeating the process for all specimens in the dataset (leave-one-out cross-validation) [10].
Finally, the test dataset is used to validate how the method (training set+validation set) predicts data that are not in the database. Therefore, it can be considered representative of the model's predictive potential [37].
Performance metrics for machine learning
Depending on the type of algorithm, different metrics should be chosen to evaluate its performance [56]. For regression models, common metrics include mean squared error, mean absolute error, root mean squared error, and r2 [35]. For classification models, common metrics are obtained from a confusion matrix, which unfortunately is not always provided in studies. Common metrics include accuracy, AUC and AUC precision (positive predictive value), recall (sensitivity), negative predictive value and specificity [58]. The F1-score and Matthews correlation coefficient are also metrics to be considered, especially in imbalanced datasets [27]. It is important to ensure that the positive reference is correctly identified in order to avoid confusion when evaluating model performance. For example, in a comparison of euploidy, it may seem obvious that the aneuploid group should be considered as the negative reference. However, the computer may mistakenly assign the aneuploid group as the positive reference if not explicitly specified, such as in cases where alphabetical ordering is used. Therefore, it is crucial to carefully define the positive and negative references before assessing a model’s performance.
Conclusions: time to implement?
Different authors have expressed their thoughts on whether or not to implement predictive AI models into the daily practice [59-61]. From my point of view, it is worth considering implementing an algorithm if its result is robust enough to answer the initial question of the requirement. For instance, if the objective was to improve the implantation rate, it is not as crucial whether the embryo selection model is based on viability, genetics, or a combination of both [36,40], nor is the specific value of AUC achieved particularly relevant. While a better AUC is theoretically associated with a better implantation outcome, this cut-off value would not be relevant if the implantation rate with the AI score is superior to that without AI. Nevertheless, external validation should be carried out to verify that the response to the requirement for integrating an AI system in the laboratory is truly satisfactory when applying AI compared to not applying AI. From there, it will be necessary to consider verifying the data either prospectively or in a multi-center setting.